Bias dan Variance dalam Machine Learning: Pengertian, Hubungan, dan Dampaknya pada Model
Sumber: [Sumber Gambar]
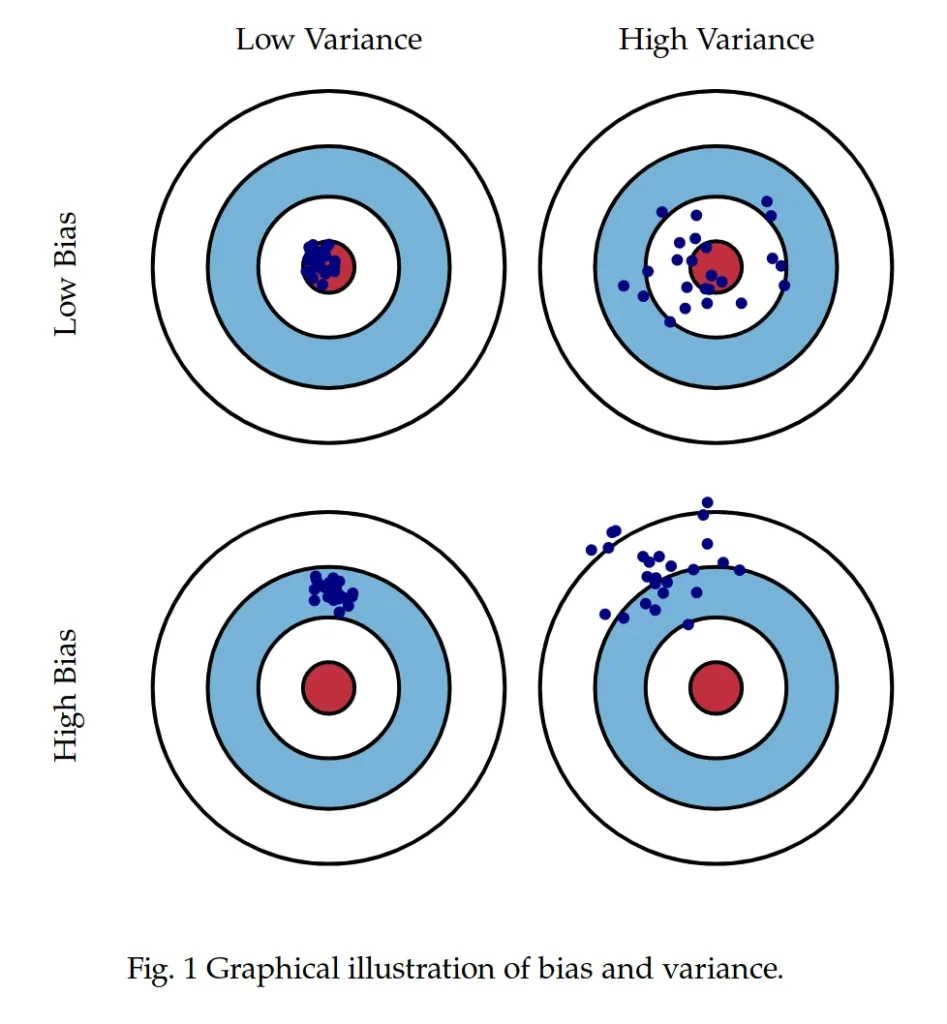
Pengantar Bias dan Variance
Dalam machine learning, bias dan variance adalah dua konsep penting yang menggambarkan sumber kesalahan dalam model prediktif. Memahami bias dan variance sangat penting untuk membangun model yang akurat dan generalisasi yang baik. Bias dan variance sering kali berhubungan erat dengan masalah underfitting dan overfitting, yang dapat memengaruhi performa model.
Artikel ini akan membahas pengertian bias dan variance, hubungan antara keduanya, dampaknya pada model machine learning, serta cara menyeimbangkan keduanya untuk mencapai model yang optimal.
Pengertian Bias
Bias adalah kesalahan yang terjadi karena model terlalu sederhana dan tidak mampu menangkap pola yang kompleks dalam data. Bias tinggi biasanya terjadi ketika model underfitting, yaitu model tidak cocok dengan data pelatihan dengan baik. Model dengan bias tinggi cenderung memiliki akurasi yang rendah baik pada data pelatihan maupun data uji.
Contoh: Jika kita menggunakan model regresi linear untuk memprediksi data yang sebenarnya memiliki pola non-linear, model tersebut akan memiliki bias tinggi karena tidak mampu menangkap pola yang kompleks.
Pengertian Variance
Variance adalah kesalahan yang terjadi karena model terlalu kompleks dan terlalu sensitif terhadap data pelatihan. Variance tinggi biasanya terjadi ketika model overfitting, yaitu model terlalu cocok dengan data pelatihan tetapi gagal melakukan generalisasi pada data baru. Model dengan variance tinggi cenderung memiliki akurasi yang tinggi pada data pelatihan tetapi rendah pada data uji.
Contoh: Jika kita menggunakan model decision tree dengan kedalaman yang sangat tinggi, model tersebut akan memiliki variance tinggi karena terlalu detail dalam mempelajari data pelatihan, termasuk noise atau outlier.
Hubungan Antara Bias dan Variance
Bias dan variance memiliki hubungan yang saling bertolak belakang. Ketika kita mengurangi bias, variance cenderung meningkat, dan sebaliknya. Hubungan ini dikenal sebagai trade-off bias-variance. Tujuan utama dalam machine learning adalah menemukan keseimbangan antara bias dan variance untuk mencapai model yang optimal.
Trade-off Bias-Variance:- Bias Tinggi, Variance Rendah: Model terlalu sederhana, underfitting.
- Bias Rendah, Variance Tinggi: Model terlalu kompleks, overfitting.
- Bias dan Variance Seimbang: Model optimal, generalisasi yang baik.
Dampak Bias dan Variance pada Model
Bias dan variance memengaruhi performa model dalam berbagai cara:
1. Underfitting (Bias Tinggi)
Ciri-ciri:- Akurasi rendah pada data pelatihan dan data uji.
- Model terlalu sederhana, tidak mampu menangkap pola data.
- Meningkatkan kompleksitas model (misalnya, menambah fitur atau menggunakan algoritma yang lebih kompleks).
- Mengurangi regularisasi.
2. Overfitting (Variance Tinggi)
Ciri-ciri:- Akurasi tinggi pada data pelatihan, tetapi rendah pada data uji.
- Model terlalu kompleks, terlalu sensitif terhadap data pelatihan.
- Mengurangi kompleksitas model (misalnya, mengurangi jumlah fitur atau mengurangi kedalaman decision tree).
- Meningkatkan regularisasi.
- Menggunakan teknik cross-validation.
Menyeimbangkan Bias dan Variance
Untuk mencapai model yang optimal, kita perlu menyeimbangkan bias dan variance. Berikut adalah beberapa teknik yang dapat digunakan:
1. Validasi Silang (Cross-Validation)
Cross-validation membantu mengevaluasi performa model pada data yang tidak terlihat selama pelatihan, sehingga mengurangi risiko overfitting.
2. Regularisasi
Regularisasi adalah teknik untuk mengurangi kompleksitas model dengan menambahkan penalti pada parameter model. Contohnya adalah L1 regularization (Lasso) dan L2 regularization (Ridge).
3. Pemilihan Model yang Tepat
Pilih model yang sesuai dengan kompleksitas data. Misalnya, gunakan model yang lebih sederhana untuk data dengan pola yang sederhana, dan model yang lebih kompleks untuk data dengan pola yang kompleks.
4. Penambahan Data
Menambah jumlah data pelatihan dapat membantu mengurangi variance, terutama pada model yang kompleks.
Contoh Praktis: Analisis Bias dan Variance
Misalkan kita memiliki dataset dengan pola non-linear dan mencoba memprediksi menggunakan model regresi linear dan decision tree.
1. Model Regresi Linear:- Bias Tinggi: Model terlalu sederhana, tidak mampu menangkap pola non-linear.
- Variance Rendah: Model tidak terlalu sensitif terhadap perubahan kecil dalam data pelatihan.
- Hasil: Underfitting, akurasi rendah pada data pelatihan dan data uji.
- Bias Rendah: Model mampu menangkap pola non-linear dengan baik.
- Variance Tinggi: Model terlalu kompleks, terlalu sensitif terhadap data pelatihan.
- Hasil: Overfitting, akurasi tinggi pada data pelatihan tetapi rendah pada data uji.
- Bias dan Variance Seimbang: Model mampu menangkap pola data tanpa terlalu kompleks.
- Hasil: Generalisasi yang baik, akurasi tinggi pada data pelatihan dan data uji.
Kesimpulan
Bias dan variance adalah dua konsep penting dalam machine learning yang menggambarkan sumber kesalahan dalam model prediktif. Memahami hubungan antara bias dan variance serta dampaknya pada model sangat penting untuk membangun model yang akurat dan generalisasi yang baik.
Dengan menyeimbangkan bias dan variance melalui teknik seperti validasi silang, regularisasi, dan pemilihan model yang tepat, kita dapat mencapai model yang optimal. Mulailah dengan mempelajari dasar-dasar bias dan variance, lalu lanjutkan dengan berlatih menerapkan teknik-teknik ini pada dataset yang berbeda. Nantikan pembahasan soal-soal menarik lainnya hanya di MathAlpha.