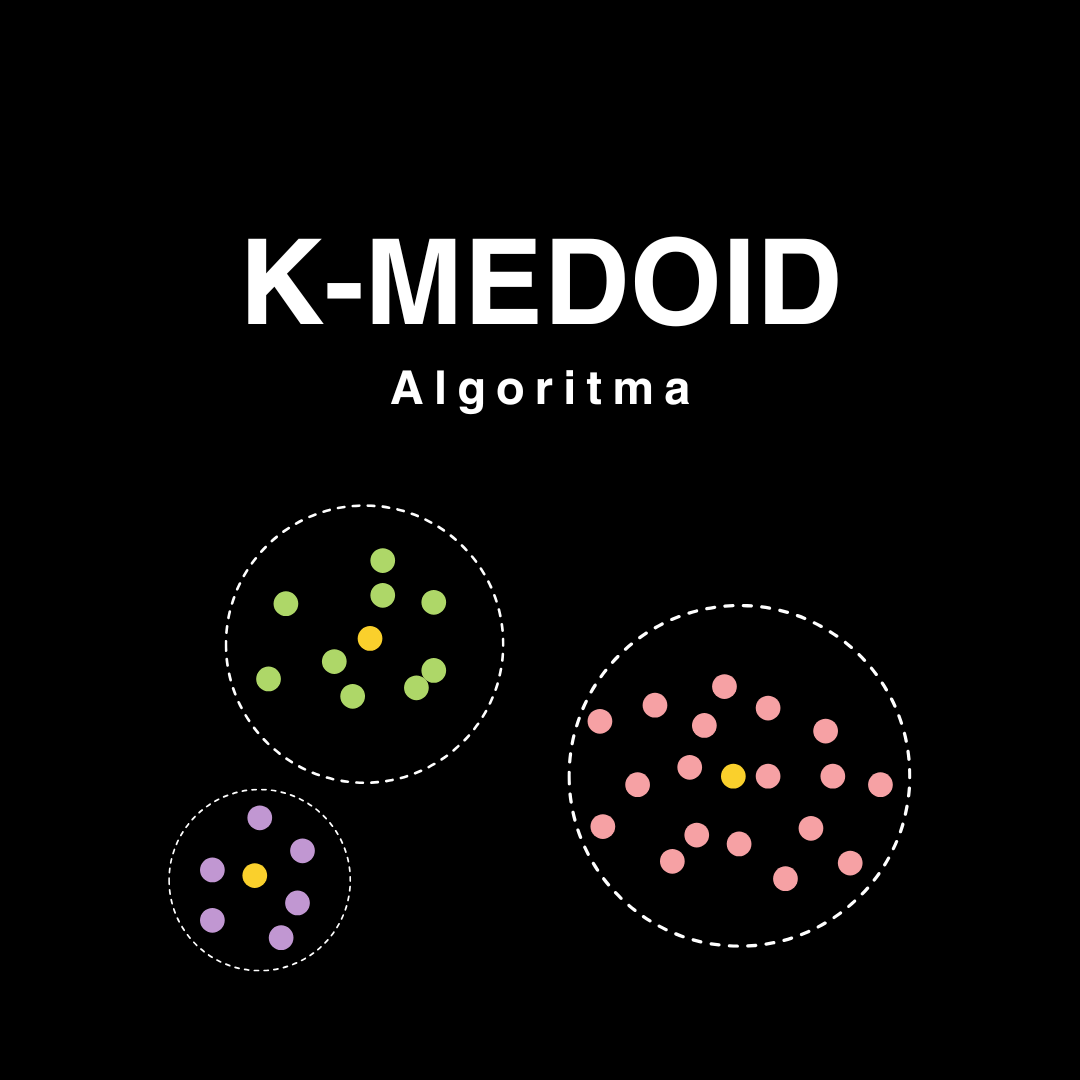
Apa itu K Medoid Clustering
Definisi K-Medoid Clustering
K-Medoid Clustering adalah algoritma unsupervised learning yang digunakan untuk mengelompokkan data ke dalam K cluster. Berbeda dengan K-Means, K-Medoid memilih data aktual sebagai pusat cluster (medoid)
sehingga lebih tahan terhadap outlier dan data yang memiliki distribusi tidak bulat.
Cara Kerja K-Medoid
- Tentukan jumlah cluster
K. - Inisialisasi medoid secara acak sebanyak
K. - Hitung jarak setiap data ke medoid, lalu tetapkan data ke cluster dengan medoid terdekat.
- Evaluasi total biaya (sum of dissimilarities) untuk setiap cluster.
- Ganti medoid dengan data lain di cluster jika penggantian tersebut mengurangi total biaya.
- Ulangi langkah 3 hingga 5 sampai medoid tidak lagi berubah atau perubahan biaya sangat kecil.
Jarak yang Digunakan
Algoritma K-Medoid umumnya menggunakan jarak berikut:
- Jarak Manhattan: \( d(x, c) = \sum_{i=1}^n |x_i - c_i| \)
- Jarak Euclidean: \( d(x, c) = \sqrt{\sum_{i=1}^n (x_i - c_i)^2} \)
Contoh Soal K-Medoid
Soal:
Diberikan dataset berikut dengan dua fitur (X1 dan X2):
Data:
+-------+------+------+
| Index | X1 | X2 |
+-------+------+------+
| 1 | 1.0 | 1.0 |
| 2 | 1.5 | 2.0 |
| 3 | 3.0 | 4.0 |
| 4 | 5.0 | 7.0 |
| 5 | 3.5 | 5.0 |
| 6 | 4.5 | 5.0 |
| 7 | 3.5 | 4.5 |
+-------+------+------+
Lakukan clustering dengan K=2. Medoid awal adalah data ke-1 (1.0, 1.0) dan ke-4 (5.0, 7.0).
Penyelesaian:
- Hitung jarak setiap titik ke medoid awal dan tetapkan cluster.
- Hitung total biaya untuk setiap cluster.
- Coba ganti medoid dengan titik lain di cluster untuk melihat apakah total biaya berkurang.
- Ulangi hingga medoid tidak lagi berubah.
Keunggulan dan Kelemahan
Keunggulan
- Lebih tahan terhadap outlier dibandingkan K-Means: Algoritma ini lebih robust terhadap outlier karena menggunakan medoid (titik data yang sebenarnya) sebagai pusat kluster. Medoid adalah titik yang memiliki nilai median jarak terendek ke semua titik lain dalam kluster, sehingga tidak mudah dipengaruhi oleh outlier seperti centroid dalam K-Means.
- Menggunakan data aktual sebagai medoid, sehingga hasil clustering lebih representatif: Dalam algoritma ini, medoid yang dipilih adalah titik data yang sebenarnya, bukan titik tengah yang dihitung secara matematis seperti pada K-Means. Hal ini membuat hasil clustering lebih representatif karena medoid benar-benar ada dalam dataset.
Kelemahan
- Kompleksitas komputasi lebih tinggi dibandingkan K-Means Karena algoritma ini harus menghitung dan membandingkan jarak antara semua pasangan titik data untuk menentukan medoid, kompleksitas komputasi menjadi lebih tinggi, terutama untuk dataset yang besar.
- Sulit digunakan untuk dataset berukuran besar tanpa optimasi tambahan:Tanpa teknik optimasi atau pendekatan heuristik, algoritma ini bisa menjadi sangat lambat dan membutuhkan banyak memori untuk dataset yang sangat besar. Oleh karena itu, implementasi yang efisien dan optimasi tambahan seringkali diperlukan untuk mengatasinya.
Implementasi K-Medoid dalam Python
Berikut adalah contoh implementasi sederhana K-Medoid menggunakan library scikit-learn:
1. Persiapan Data
import numpy as np
import pandas as pd
# Dataset contoh
data = np.array([
[1.0, 1.0],
[1.5, 2.0],
[3.0, 4.0],
[5.0, 7.0],
[3.5, 5.0],
[4.5, 5.0],
[3.5, 4.5]
])
# Jika ingin menggunakan DataFrame untuk manipulasi lebih lanjut
df = pd.DataFrame(data, columns=['X', 'Y'])
2. Menentukan Jumlah Cluster (K)
Ada beberapa metode untuk menentukan jumlah cluster (K) yang optimal. Dua metode yang sering digunakan adalah:
- Elbow Method
- Silhouette Score
Elbow Method
Metode ini melibatkan plotting dari jumlah cluster (K) yang berbeda dengan nilai "inertia" atau SSE (Sum of Squared Errors) untuk setiap nilai K, dan mencari titik elbow (titik yang mulai melandai).
import matplotlib.pyplot as plt
from sklearn_extra.cluster import KMedoids
# Menentukan range K yang akan dicoba
k_range = range(1, 11)
inertia = []
for k in k_range:
kmedoids = KMedoids(n_clusters=k, random_state=42, method='pam')
kmedoids.fit(df)
inertia.append(kmedoids.inertia_)
# Plot hasil
plt.plot(k_range, inertia, marker='o')
plt.title('Elbow Method for Optimal K (K-Medoids)')
plt.xlabel('Jumlah Cluster (K)')
plt.ylabel('Inertia')
plt.show()
Silhouette Score
Silhouette Score memberikan informasi tentang seberapa baik setiap titik data terklaster. Nilai skor berkisar antara -1 dan 1, dimana nilai yang lebih tinggi menunjukkan pemisahan yang lebih baik antar cluster.
from sklearn.metrics import silhouette_score
silhouette_scores = []
for k in k_range[1:]: # K=1 tidak memiliki silhouette score
kmedoids = KMedoids(n_clusters=k, random_state=42, method='pam')
kmedoids.fit(df)
score = silhouette_score(df, kmedoids.labels_)
silhouette_scores.append(score)
# Plot hasil
plt.plot(k_range[1:], silhouette_scores, marker='o')
plt.title('Silhouette Scores for Optimal K (K-Medoids)')
plt.xlabel('Jumlah Cluster (K)')
plt.ylabel('Silhouette Score')
plt.show()
3. Melakukan K-Medoid dengan K Optimal
Setelah menentukan K yang optimal menggunakan Elbow Method atau Silhouette Score, kita dapat melanjutkan untuk melakukan clustering.
# Menentukan jumlah cluster berdasarkan metode sebelumnya (misalnya, K=3)
kmedoids = KMedoids(n_clusters=3, random_state=42, method='pam')
kmedoids.fit(df)
# Output hasil clustering
print("Medoid:", kmedoids.cluster_centers_)
print("Label:", kmedoids.labels_)
4. Visualisasi
plt.scatter(df['X'], df['Y'], c=kmedoids.labels_, cmap='viridis')
plt.scatter(kmedoids.cluster_centers_[:, 0], kmedoids.cluster_centers_[:, 1], s=200, c='red', marker='X')
plt.title('Hasil Clustering dengan K-Medoids')
plt.xlabel('X')
plt.ylabel('Y')
plt.show()
5. Evaluasi Model
Jika kita tahu nilai sebenarnya dari label cluster (misalnya, jika ini adalah tugas semi-supervised), kita bisa mengevaluasi model menggunakan metrik seperti Homogeneity, Completeness, dan V-Measure. Namun, dalam clustering unsupervised, metrik ini sering tidak tersedia.
from sklearn.metrics import homogeneity_score, completeness_score, v_measure_score
# Misalnya, kita memiliki label sebenarnya (true_labels)
true_labels = np.array([0, 0, 1, 1, 2, 2, 2]) # Ganti dengan label yang sesuai
print("Homogeneity:", homogeneity_score(true_labels, kmedoids.labels_))
print("Completeness:", completeness_score(true_labels, kmedoids.labels_))
print("V-Measure:", v_measure_score(true_labels, kmedoids.labels_))