K-Nearest Neighbors (KNN): Pengertian, Cara Kerja, dan Implementasi dalam Python
Sumber: [Sumber Gambar]
Definisi K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) adalah salah satu algoritma supervised learning yang digunakan untuk tugas klasifikasi dan regresi. Algoritma ini termasuk dalam kategori lazy learning, karena tidak membuat model selama fase pelatihan. Sebaliknya, KNN menyimpan seluruh dataset dan melakukan prediksi dengan mencari data tetangga terdekat dari suatu data baru berdasarkan metrik jarak tertentu, seperti jarak Euclidean, Manhattan, atau lainnya.
Dalam klasifikasi, KNN menentukan label data baru berdasarkan mayoritas label dari tetangga terdekatnya. Sedangkan dalam regresi, KNN menghitung rata-rata nilai target dari tetangga terdekat untuk memprediksi nilai data baru.
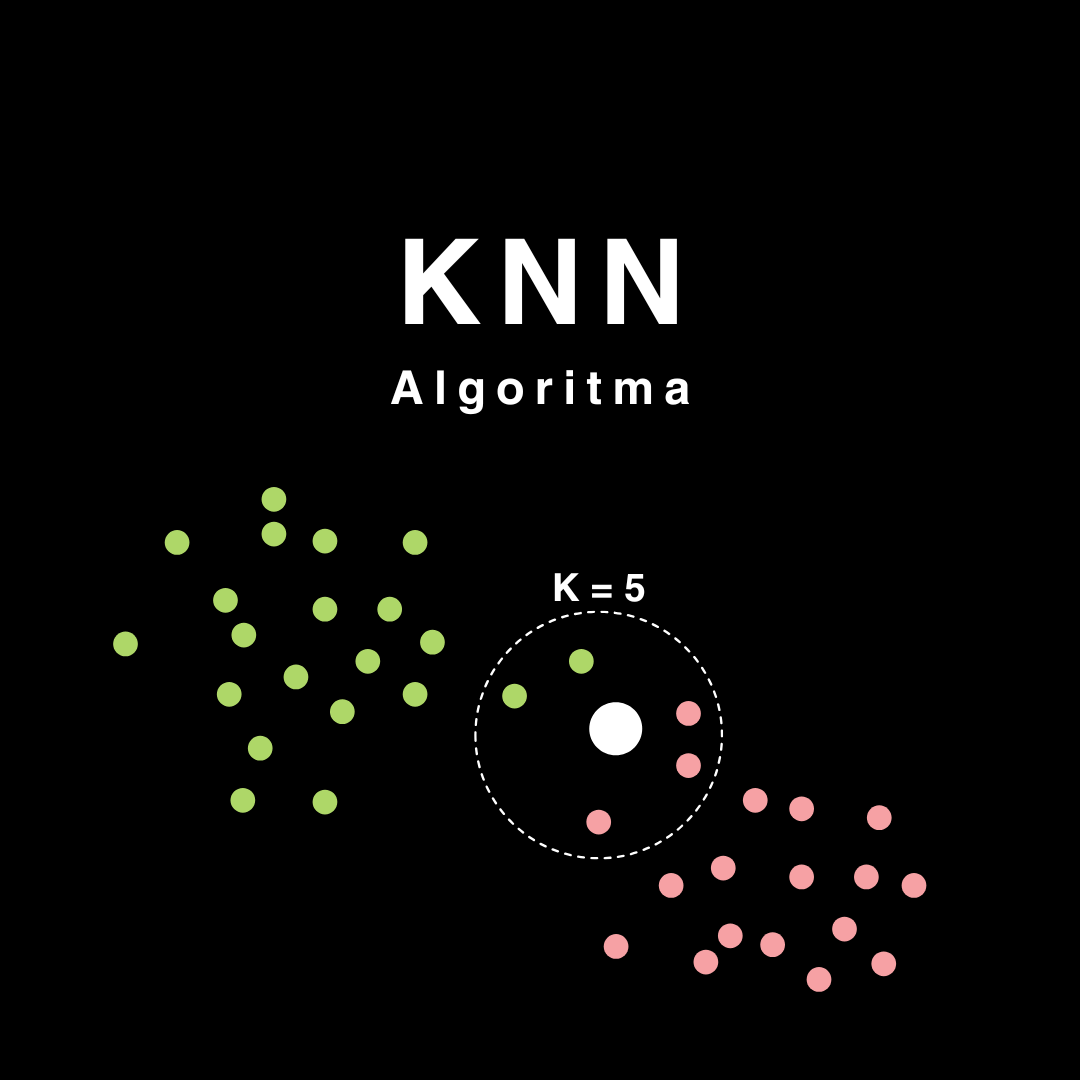
Cara Kerja KNN
Algoritma KNN bekerja dengan langkah-langkah berikut:
-
Tentukan parameter
K: Pilih jumlah tetangga terdekat (K) yang akan digunakan untuk prediksi. NilaiKbiasanya dipilih secara eksperimen atau menggunakan teknik validasi silang. - Hitung jarak: Hitung jarak antara data baru dengan semua data dalam dataset menggunakan metrik jarak tertentu, seperti jarak Euclidean atau Manhattan.
- Urutkan data: Urutkan data berdasarkan jarak terdekat ke data baru.
- Pilih tetangga terdekat: Pilih
Ktetangga terdekat dari data baru. -
Prediksi:
- Untuk klasifikasi: Tentukan label mayoritas dari tetangga terdekat.
- Untuk regresi: Hitung rata-rata nilai target dari tetangga terdekat.
Metrik Jarak yang Umum Digunakan
Metrik jarak digunakan untuk mengukur seberapa dekat dua titik data dalam ruang multidimensi. Beberapa metrik jarak yang umum digunakan dalam KNN adalah:
- Jarak Euclidean: \[ \sqrt{\sum_{i=1}^n (x_i - y_i)^2} \] Jarak Euclidean adalah metrik jarak paling umum yang digunakan untuk mengukur jarak lurus antara dua titik dalam ruang Euclidean.
- Jarak Manhattan: \[ \sum_{i=1}^n |x_i - y_i| \] Jarak Manhattan mengukur jarak antara dua titik dengan menjumlahkan selisih absolut dari koordinat mereka. Metrik ini sering digunakan dalam dataset dengan fitur yang memiliki skala berbeda.
Contoh Soal KNN
Berikut adalah contoh sederhana penggunaan KNN untuk klasifikasi:
Soal:
Diberikan dataset berikut dengan dua fitur (X1 dan X2) dan label:
Data:
+-------+------+-------+-------+
| Index | X1 | X2 | Label |
+-------+------+-------+-------+
| 1 | 2.0 | 4.0 | A |
| 2 | 4.0 | 2.0 | B |
| 3 | 4.0 | 4.0 | A |
| 4 | 6.0 | 4.0 | B |
+-------+------+-------+-------+
Jika data baru adalah (X1=5.0, X2=4.5) dan menggunakan K=3, tentukan label data baru dengan menggunakan jarak Euclidean.
Penyelesaian:
- Hitung jarak Euclidean dari data baru ke setiap data dalam dataset:
- Urutkan data berdasarkan jarak terdekat:
- Pilih 3 tetangga terdekat (K=3): Data 3, Data 4, Data 2.
- Mayoritas label dari tetangga: Data 3 (A), Data 4 (B), Data 2 (B). Maka, label mayoritas adalah B.
Jarak ke Data 1: \( \sqrt{(5.0 - 2.0)^2 + (4.5 - 4.0)^2} = \sqrt{9 + 0.25} = 3.04 \)
Jarak ke Data 2: \( \sqrt{(5.0 - 4.0)^2 + (4.5 - 2.0)^2} = \sqrt{1 + 6.25} = 2.5 \)
Jarak ke Data 3: \( \sqrt{(5.0 - 4.0)^2 + (4.5 - 4.0)^2} = \sqrt{1 + 0.25} = 1.12 \)
Jarak ke Data 4: \( \sqrt{(5.0 - 6.0)^2 + (4.5 - 4.0)^2} = \sqrt{1 + 0.25} = 1.12 \)
1. Data 3 (1.12)
2. Data 4 (1.12)
3. Data 2 (2.5)
4. Data 1 (3.04)Jawaban: Data baru diklasifikasikan sebagai B.
Penerapan KNN dalam Machine Learning
KNN adalah algoritma yang serbaguna dan dapat diterapkan dalam berbagai bidang, seperti:
- Klasifikasi Gambar: KNN digunakan untuk mengelompokkan gambar berdasarkan kemiripan fitur, seperti warna, tekstur, atau bentuk. Fitur-fitur ini diekstraksi dari gambar menggunakan algoritma tertentu, dan kemudian setiap gambar direpresentasikan sebagai vektor dalam ruang multidimensi. Jarak antara vektor menentukan kelompok gambar tersebut.
- Pengenalan Wajah: KNN digunakan dengan membandingkan vektor fitur wajah yang diekstraksi menggunakan algoritma seperti PCA atau deep learning. Setiap wajah direpresentasikan sebagai titik dalam ruang multidimensi, dan jarak antara vektor wajah menentukan seberapa mirip wajah tersebut dengan wajah dalam dataset pelatihan.
- Sistem Rekomendasi: Dalam sistem rekomendasi, KNN digunakan untuk menemukan pengguna atau item yang mirip berdasarkan preferensi, ulasan, atau karakteristik lainnya. Misalnya, untuk merekomendasikan film, algoritma ini mencari pengguna dengan preferensi serupa dan menyarankan film yang mereka sukai.
- Analisis Data Medis: Dalam analisis data medis, KNN digunakan untuk mengelompokkan pasien berdasarkan kesamaan gejala atau hasil tes. Hal ini membantu dalam diagnosis penyakit atau rekomendasi pengobatan berdasarkan riwayat pasien lain yang serupa.
Keuntungan dan Kerugian KNN
Keuntungan
- Mudah diimplementasikan: Algoritma KNN sangat sederhana dan mudah dipahami, sehingga implementasinya cukup mudah bahkan untuk pemula.
- Tidak memerlukan asumsi khusus tentang data: KNN tidak membuat asumsi apa pun tentang distribusi data yang mendasarinya, sehingga dapat digunakan dalam berbagai jenis dataset.
- Fleksibel untuk klasifikasi dan regresi: KNN dapat digunakan untuk kedua tugas ini, sehingga sangat serbaguna dan dapat diterapkan pada berbagai masalah.
Kerugian
- Kompleksitas komputasi tinggi untuk dataset besar: Ketika dataset menjadi sangat besar, perhitungan jarak antara titik data menjadi sangat memakan waktu dan membutuhkan banyak daya komputasi.
- Sensitif terhadap skala fitur: Fitur dengan skala yang lebih besar dapat mendominasi perhitungan jarak, sehingga normalisasi data diperlukan untuk memastikan bahwa semua fitur berkontribusi secara seimbang.
- Memerlukan penyimpanan seluruh dataset selama inferensi: KNN harus menyimpan seluruh dataset untuk melakukan prediksi, yang berarti memori yang dibutuhkan bisa sangat besar, terutama untuk dataset yang besar.
Implementasi KNN dalam Python
Berikut adalah contoh implementasi KNN untuk klasifikasi menggunakan library scikit-learn:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
Load dataset
iris = load_iris()
X, y = iris.data, iris.target
Bagi data menjadi training dan testing
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Buat model KNN dengan K=3
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
Prediksi data testing
y_pred = knn.predict(X_test)
Hitung akurasi
accuracy = accuracy_score(y_test, y_pred)
print(f"Akurasi model: {accuracy * 100:.2f}%")
Dalam contoh di atas, dataset Iris digunakan untuk melatih model KNN dengan K=3. Model kemudian diuji pada data testing, dan akurasi dihitung untuk mengevaluasi performa model.